

OCRText
- Tesseract 4.0(LSTM)
- Windows
- ABBYY
- Abbyy クラウド
- Google クラウド
- Microsoft クラウド
- Amazon クラウド
既定の言語は「英語」です。
ポート
OCRTextコンポーネントは、既定でコントロール入力ポート、コントロール出力ポート、データ入力ポート、データ出力ポートを持っています。
| ポート | 説明 |
|---|---|
| Control In(コントロール入力) | 1つ以上のコンポーネントのコントロール出力ポートに接続する必要があります。 |
| Control Out(コントロール出力) | 他のコンポーネントまたはコネクタのコントロール入力ポートに接続できます。 |
| Data In (データ入力) - ビットマップ | 他のコンポーネントまたはコネクタのデータ入力ポートに接続できます。 |
| Data Out (データ出力) - 文字列 | 抽出されたテキスト(文字列)を返します。 |
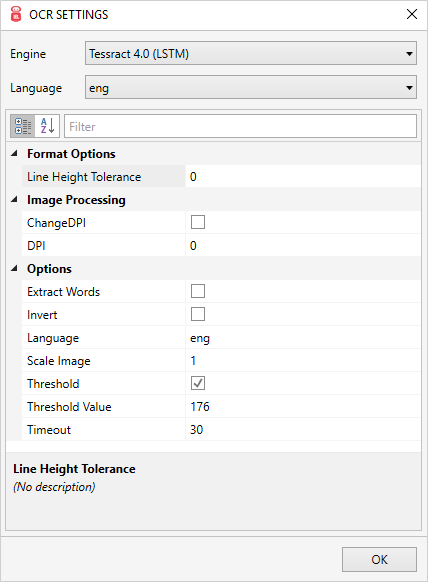
プロパティ
次のプロパティを編集できます。
| プロパティ | 説明 |
|---|---|
| Search | それぞれのプロパティを検索します。 |
| Delay After Execution | アクションが実行された後(秒単位)の待機時間を指定します。 |
| Delay Before Execution | アクションが実行されるまでの待機時間(秒単位)を指定します。 |
| Name | |
| Image Source | Image Source(画像ソース)には2つのオプションが表示されます: |
例
画像からのテキストを抽出する例を見てみましょう。

テキストを抽出するには:
まず、ReadFromFile コンポーネントを使用して、次のように読み取ることができる画像を OCR テキストに提供します。
Toolbox でActions を展開します。OCRText コンポーネントをデザインサーフェイスにドラッグアンドドロップします。
- Generalを展開し、Showコンポーネントをデザインサーフェイスにドラッグアンドドロップします。
Start コンポーネントとReadfromFile コンポーネント間のコントロール ポート。ReadfromFile コンポーネントのコントロール出力 ポート をOCRText コンポーネントのコントロール入力ポート へ。ReadfromFile コンポーネントのデータ出力ポート をOCRText コンポーネントのデータ入力ポート へ。OCRText コンポーネントのデータ出力ポート をShow コンポーネントのデータ入力ポート へ。- Messageboxコンポーネントのコントロール出力ポートをEndコンポーネントのコントロール入力ポート へ。
Copyright © Enzan Trades Inc. All rights reserved.